Quel impact a aujourd’hui le travail du data-science dans les usages ?
Au quotidien, on peut observer quelques impacts significatifs dans le rapport que les individus entretiennent avec la technologie et notamment l’IA grâce à la data-science. Par exemple, avec Google et son algorithme de réponse prédictive, on facilite et on optimise la réponse à des mails. Ce type de traitement va se démocratiser de plus en plus. Ces applications du machine learning vont être présentes partout dans notre quotidien pour faciliter la vie de tous. Pour certains, l’intelligence artificielle deviendra bientôt aussi invisible que l’électricité aujourd’hui.

On observe le même phénomène pour internet qui a pris une place prépondérante aujourd’hui et cela nous paraît tout à fait normal. On peut prédire que le machine et le deep learning auront le même impact et que, dans quelques années, ces algorithmes seront tellement ancrés dans notre quotidien qu’ils en deviendront invisibles.
Quelles évolutions voyez-vous dans votre travail de data-scientist ?
Chez Ellisphere, nous utilisons actuellement des outils technologiques efficaces qui ont déjà fait leurs preuves. Le choix de ces technologies s’explique par la nécessité d’expliquer le traitement de la donnée. En termes d’avancées technologiques, les évolutions que va connaître le métier risquent d’être très importantes.
Si on met de côté l’explicabilité, nous disposons encore d’une très grande marge de progression vis-à-vis des innovations technologiques actuelles. Nous sommes dans une époque où les découvertes pour améliorer les technologies, notamment autour du deep learning, vont très vite. L’état de l’art ne sera pas un blocage de sitôt.
Pour en revenir à l’explicabilité, il existe beaucoup moins de recherche à ce sujet. Objectivement, la question que l’on doit se poser aujourd’hui est de savoir si les technologies de deep learning pourront être expliquées demain, ou si finalement, les performances de ces technologies seront admises et n’auront plus besoin d’être explicitées.
Existe-t-il des limites à cette évolution ?
Il existe actuellement de nombreux aspects sur lesquels cette évolution peut être ralentie. Si je prends l’exemple d’Ellisphere, les législations jouent un rôle fondamental dans le traitement de la donnée. Certaines techniques ne peuvent être utilisées, car elles contreviennent à la nécessité de pouvoir expliquer l’algorithme à un humain. Donc, d’un point de vue strictement réglementaire, certains domaines d’activités seront impactés et limités dans l’usage de la donnée.
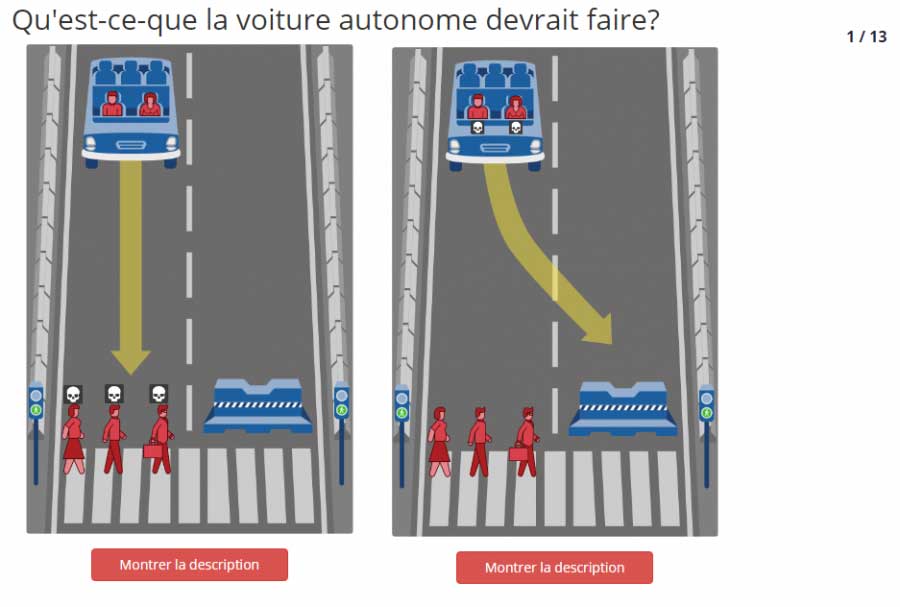
Une autre problématique qui risque de se poser dans l’évolution de ces technologies, c’est celle de l’éthique. Prenons l’exemple des voitures autonomes. En théorie, la promesse est géniale. On vous promet d’éviter tous les accidents de la route et in fine de sauver des vies grâce à la technologie. Aujourd’hui, nous sommes aux balbutiements de ce phénomène.
Cependant, comme tout système informatique, si cela fonctionne 99,9% du temps, quand cela ne va pas fonctionner, la question de la responsabilité se posera forcément. Le choix éthique que cette situation peut poser est intéressant. La voiture détecte une personne devant elle, est-ce qu’elle doit sacrifier son occupant ou la personne qu’elle risque de percuter ? (cf. la simulation Moral Machine du MIT).
Pensez-vous que nous allons vers une fin de l’explicabilité du traitement de la donnée ?
Pour l’instant, nous n’allons pas du tout dans cette direction si on se fie aux législations. Les mentalités européennes sont très différentes de ce que l’on peut trouver aux États-Unis et en Chine. Cela peut s’avérer bloquant et freiner notre progression, car nous avons des contraintes au niveau de l’utilisation de la donnée que d’autres grandes puissances n’ont pas.
En Europe, avant de faire quoi que ce soit, on se réfère automatiquement au droit. On s’occupe de la régulation avant de passer à la production. Cela nous fait perdre beaucoup de temps. Aux États-Unis ou en Chine, la problématique est différente. Généralement, ils commencent par lancer les technologies, et une fois que les premiers problèmes vont se poser (éthiques ou techniques), ils vont se questionner sur la régulation.
Si on prend l’exemple de Facebook, au lancement de la plateforme, personne ne s’est posé la question de savoir si la récupération puis la vente de données personnelles à des organismes privés posaient un problème éthique. Il a fallu des scandales tels que Cambridge Analytica ou encore l’entrée en vigueur du RGPD en Europe pour que ces questions soient mises sur le devant de la scène.
C’est tout l’enjeu de la société actuelle et de l’évolution technologique. Quel curseur place-t-on entre les innovations technologiques et la liberté ? Si on prend l’exemple de la reconnaissance faciale, la Chine a énormément d’avance sur l’Europe. Cependant, on peut se questionner sur l’éthique que pose cette utilisation (score social, surveillance généralisée).
Doit-on poser les limites de l’usage technologique pour garantir un équilibre ou doit-on aller toujours plus loin au risque de créer des dérives ? Je pense que ce sont des questions passionnantes qui se posent dès aujourd’hui à notre métier de data-scientist.



